项目地址:https://github.com/Anko233/wc/blob/master/wc.py
拿到题目后,发现这个作业需要打开文件,使用正则表达式匹配,接受命令行参数等操作,于是就有搜索引擎查找了许多有关这方面的内容.
整体设计思路是使用命令行参数进行for循环,再使用if-elif-else进行匹配,每个命令行参数的实现做成一个函数
实现了-a -c -l -w 的功能
-l 功能:只需要打开文件,然后使用 for循环读取文件,每读取一次计数器加一,就能得出结果
def line(f):#计算行数的函数 i = 0 for line in f: i += 1 print("Line number is ", i)
-c 功能:使用read()函数,再使用len()函数,即可读取字符数(我认为\n也算是一个字符)
def character(f):#计算字符数的函数 print("Character number is ", len(f.read())) 之前想过用正则表达式识别\n,但是后来发现代码中也可能包含\n,这样计数就会出现错误
-w 功能:使用正则表达式找出所有的词数,用findall()返回一个列表,再用len()计算数量
def word(f):#计算单词数的函数 w = re.compile("[a-z]+", re.I).findall(f.read()) print("Word number is ",len(w)) -a 基本思路是先判断是否为空行,再判断是否为单行注释,最后判断是否为注释块,都不是则为代码行,思路有些繁琐,而且对文件中有包含/*, */, //的字符串会出现识别错误
运行完一个函数后,文件对象指针指向末尾,应此要用符f.seek(0, 0)使其指向开头
测试:
空文件

单字符文件
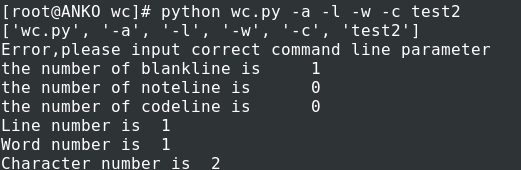
单词文件
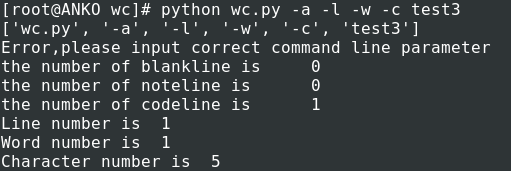
单行文件:this is a line of test4

标准文件test
已上传至github
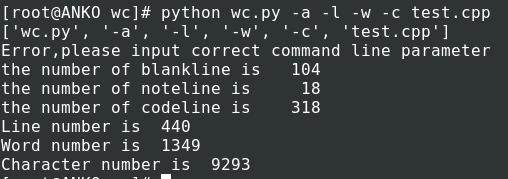
经测试包含/**/类型的注释代码正则表达式匹配会出现问题
PSP表
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
| Planning | 计划 | 10 | 5 |
| · Estimate | · 估计这个任务需要多少时间 | 10 | 5 |
| Development | 开发 | 330 | 500 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 80 |
| · Design Spec | · 生成设计文档 | 0 | 0 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 0 | 0 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 0 | 0 |
| · Design | · 具体设计 | 100 | 180 |
| · Coding | · 具体编码 | 120 | 180 |
| · Code Review | · 代码复审 | 20 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 30 |
| Reporting | 报告 | 30 | 50 |
| · Test Report | · 测试报告 | 10 | 20 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 20 |
| 合计 |
| 370 | 555 |